はじめに
株式会社GROWTH VERSEにてBE兼EpicOwnerをしている川田です。最近業務で1000万件以上の大量データのレポート作成をできるようにパフォーマンス改善のリファクタリングを実施しました。その結果、元々1000万件近くのレポート作成だと4時間近くかかっていたところを30秒程度で作成できるまで改善できました。今回のリファクタリングで色々学んだことが多かったため、私が学んだことを本記事で皆さんに共有したいなと思い執筆しました。
レポート機能の概要
レポート機能の概要について説明します。レポート機能とは一言で言うとSnowflakeで管理しているデータをsqlを使用して抽出し、その取得結果をexcelファイルに書き出す機能です。レポートを作成するためにはレポート設定を作成する必要があります。以下でレポート設定画面の画像を使用して説明します。
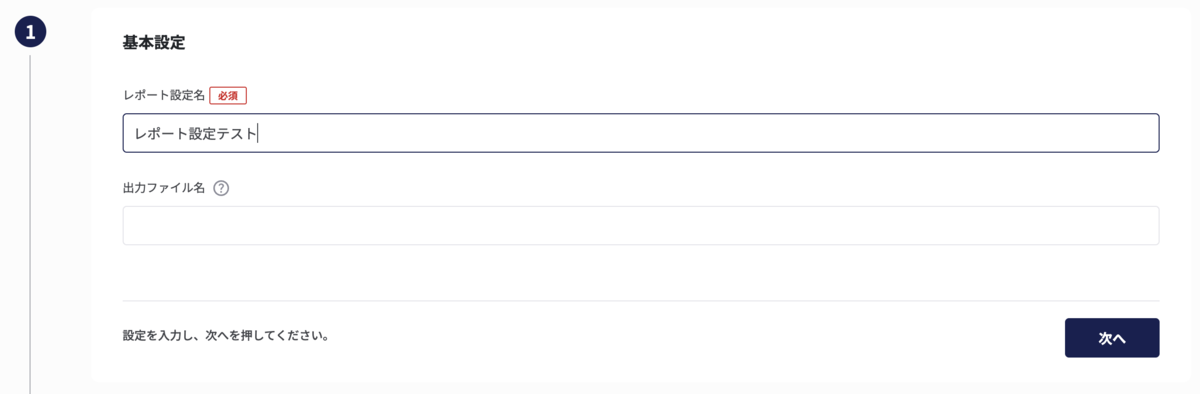
レポート設定新規作成画面ではまずレポート設定名を入力します。
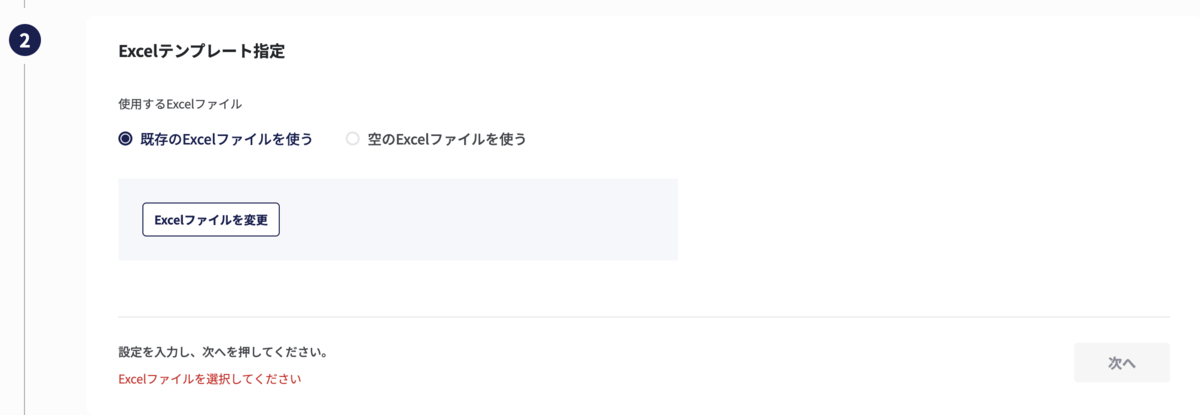
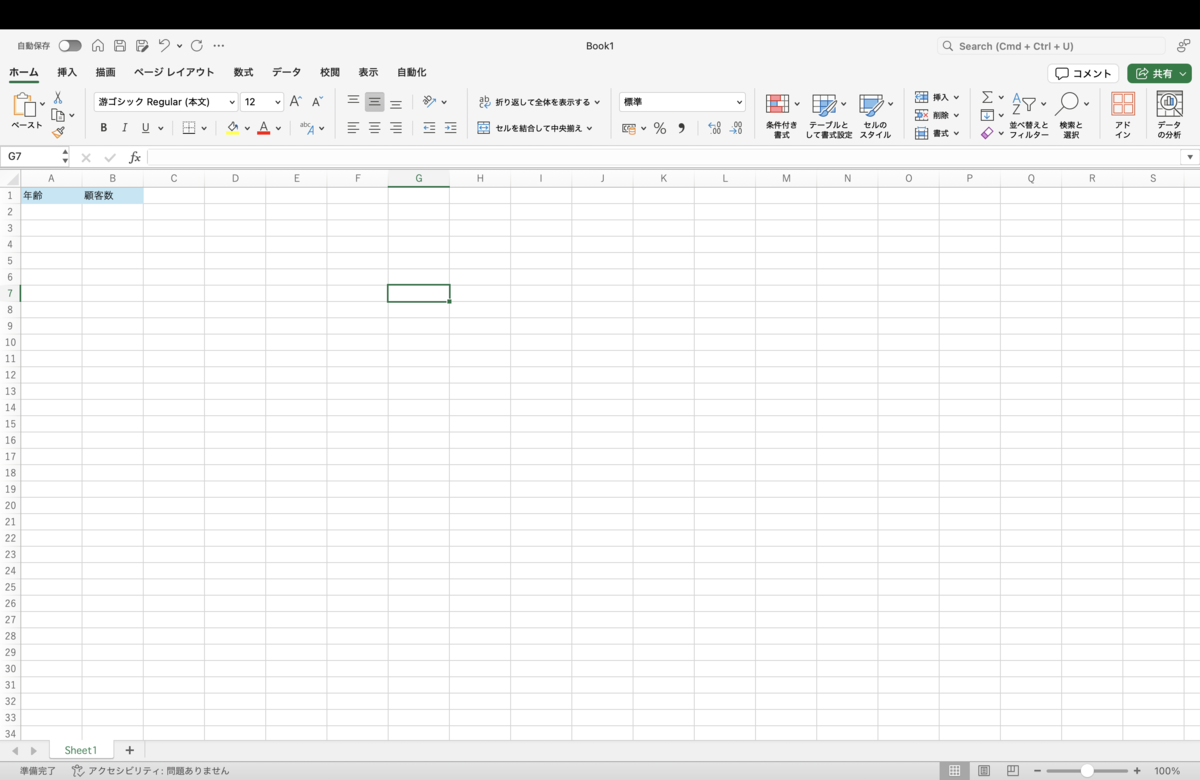
次にExcelテンプレートの指定をします。空のExcelファイルを使用するとした場合、書き出すExcelテンプレートファイルは新規のエクセルファイルとなります。一方、何らかのExcelテンプレートファイルを指定した場合は、指定したExcelテンプレートファイルに書き込み処理を実施します。例えば、簡単な例として上の画像のように出力データのヘッダーを事前にテンプレートファイルに定義するなどが考えられます。
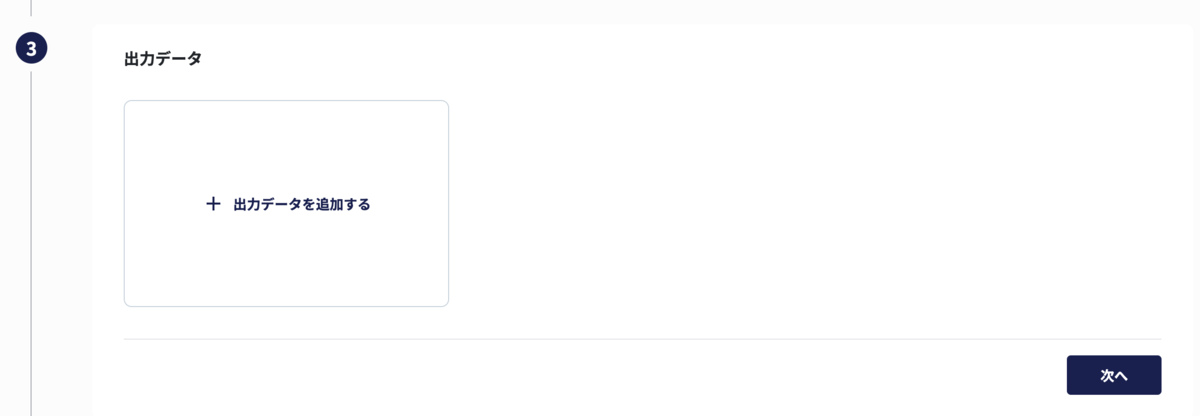
続いて出力データの出力設定を行います。出力設定はダッシュボードからチャートを選択する方法とsqlを直接入力する方法の2つがあります。以下でそれぞれの抽出方法を説明します。
ダッシュボードからチャートを選択する方法
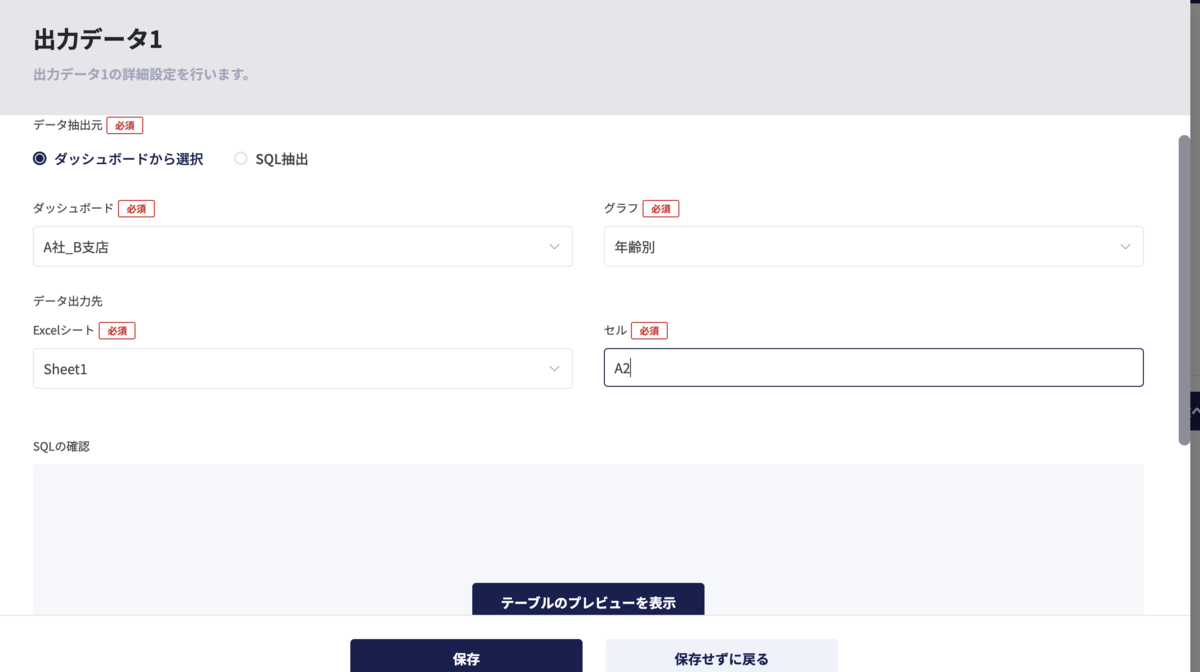
こちらはダッシュボードからチャートを選択する方法です。ダッシュボードとはaimstarのユーザーが日々確認したいチャート(例えば今週購買したユーザーの年齢別人数など)を簡単に見るための機能です。ダッシュボードで登録されているチャートのデータをレポートに書き出すためにあります。ダッシュボードとグラフを指定し、データの出力先としてExcelシートと出力開始セルを指定します。例えば、
select customer_age, count(customer_id) from customer where latest_buy_date ≥ DATEADD(week, -1, CURRENT_TIMESTAMP()) group by customer_age
上記のようなsqlが実施された場合、レポート出力は以下の状態になっているイメージです。
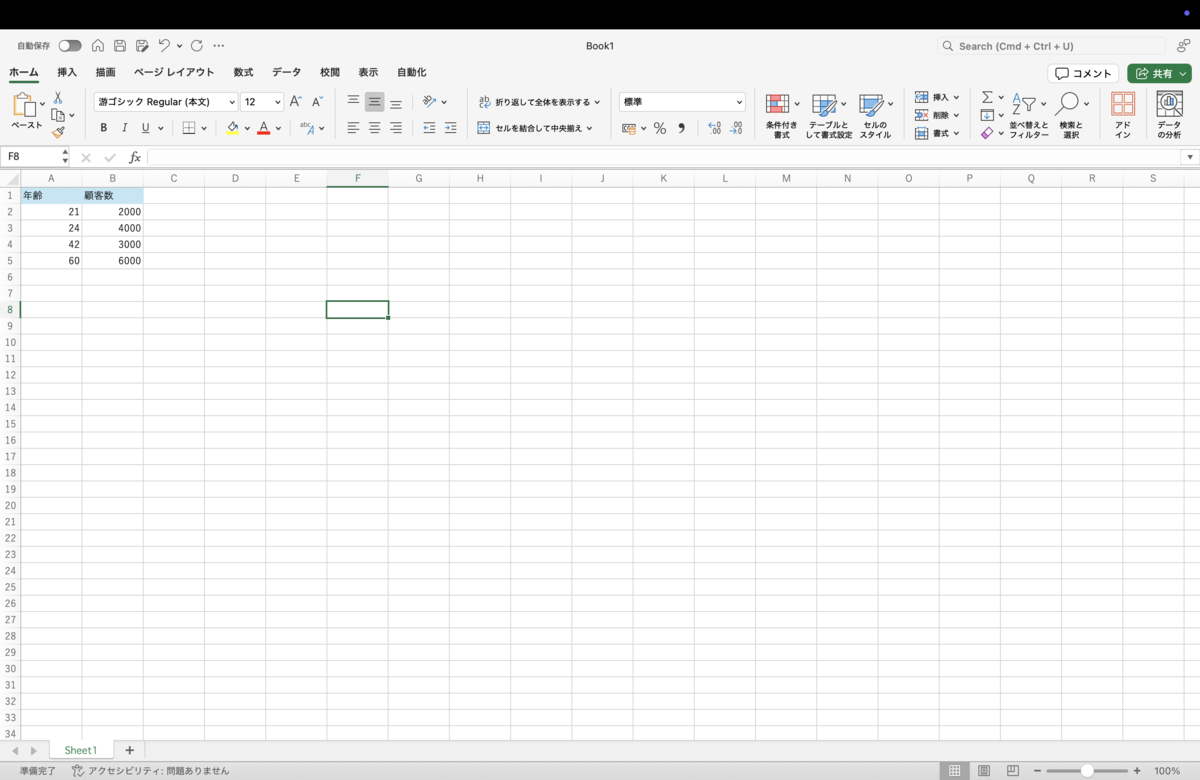
チャートを生成する上で使用されているデータが使用されています。データのプレビュー機能もあるため、どのようなデータをレポート出力するかを事前に確認することができます。
sqlから抽出する方法
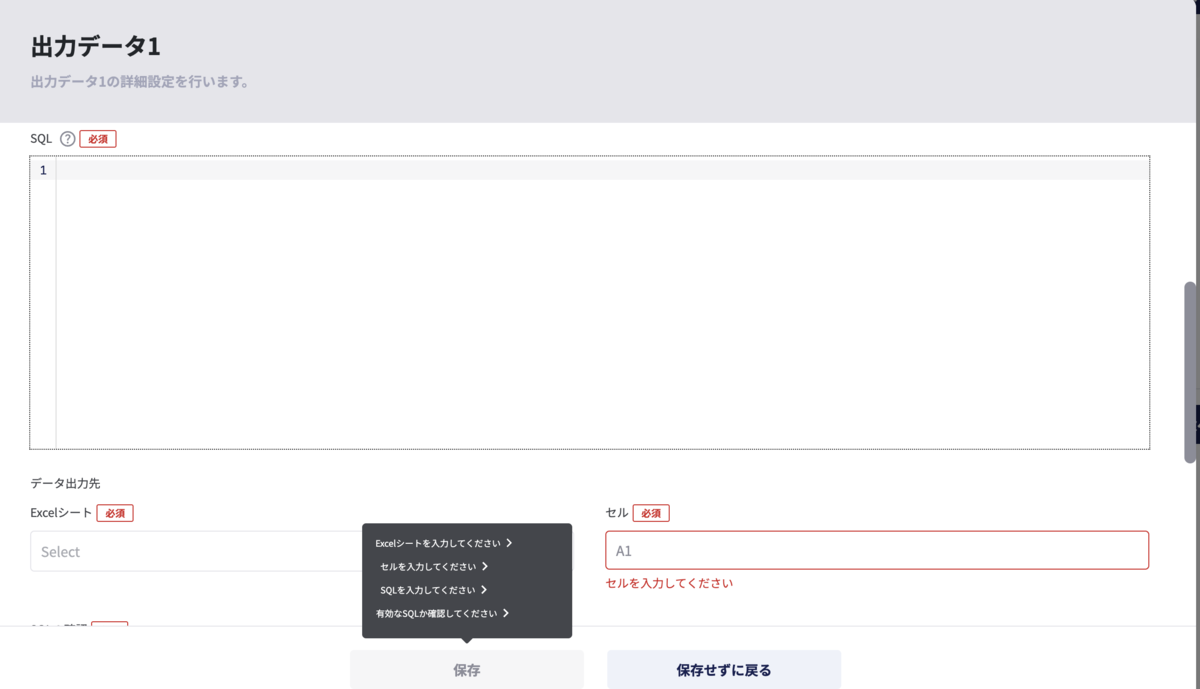
sqlからの抽出方法ではユーザーにsqlを入力していただきます。そしてExcelシートと出力開始セルを入力して保存すれば設定完了です。
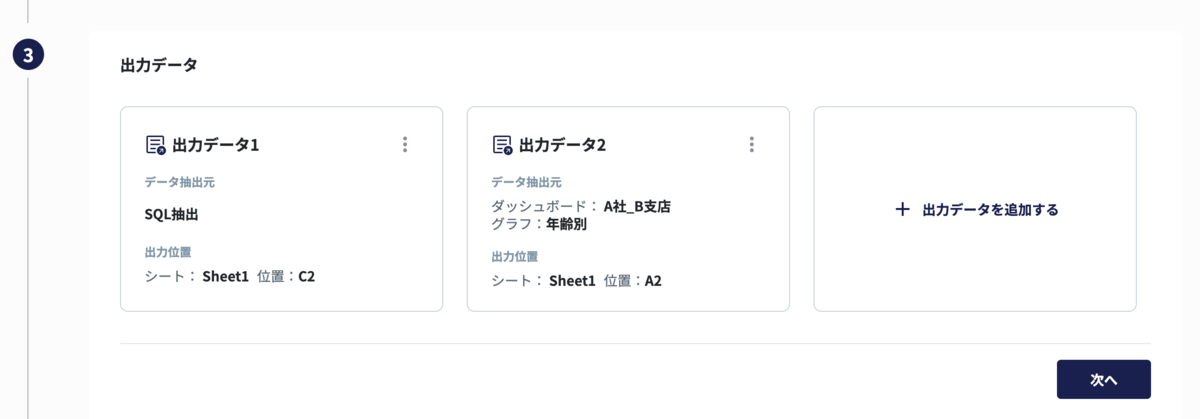
ダッシュボードからのチャート指定とsql抽出の両方を設定すると上の画像の状態になります。
最後にスケジュール設定を設定したら完了です。
レポート作成の要件
以下にレポート作成の要件を説明します。
- 前提としてユーザーにはデータ出力先のcellの重複はしないように設定していただくことを想定しているが、もし重複した場合のデータの優先度は以下の内容である。
- 性能品質として1000万件(1つのcellで1件とする)のレポート作成の実行が同時に5つ行われても問題なく運用できる状態にする。
速度改善のために取り組んだこと
1000万件のレポート作成を同時に5つ行っても耐えるためのパフォーマンス改善として以下の対応をしました。
- 全体的にappendを使用せずにindex指定による要素追加に修正
- StreamWriterを対応できるようにするためExcelテンプレートのデータ、sql抽出のデータ、ダッシュボードのチャート指定のデータを優先度を比較してマージし、1つの配列で管理する。
元々レポート作成の際はExcelizeのSetCellValueというを使用していましたが、この関数は数万件程度のレポート作成までしか対応しておらず、それ以上のレポートになるとレポート作成に失敗してしまいます。そのため、数十万件以上のレポート作成の場合はStreamWriterの使用が推奨されています。本来であればStreamWriterを使用して実装しようとしていましたが、実装中にStreamWriterには以下の2つの技術的制約があることを知りました。
- データの上書き処理ができない。例えば、A5に既にデータがあるとして、A5にStreamWriterで書き込みしようとするとエラーが発生する。
- データ作成の際は昇順で書き込みをしないといけない。例えば、A5に既にデータがあるとして、3行目にデータ書き込みができない。
そのため、一旦SetCellValueを使用したcellの書き込み処理を実施し、後からStreamWriterで書き込みするようにリファクタリングする方針になりました。書き込み順序でsort処理を実施しているのは上記2つの技術的制約があるためです。StreamWriterに関しての制約はGolangのExcelizeでStreamWriterを使用したが、SetCellValueに変更した話で解説しているため、こちらの記事もぜひご覧ください。では、それぞれの対応に関して以下で説明していきます。
全体的にappendを使用せずにindex指定による要素追加に修正
大量データではない場合、out_of_rangeの発生を防ぐためにappendを使用するのは良いと思いますが、今回のように1000万件以上のデータをサーバー側で扱う場合はindex指定による要素追加は空間計算量の観点から実施するべきだと判断しました。例えば500万件の要素を保持する配列に対してappendで要素を1件追加した場合、サーバー側では500万1件のデータを格納するためのメモリを新規で用意し、そこに500万件の既存データと追加分の1件のデータを格納した後、元々使用していた500万件分のメモリを削除するという処理が内部で発生してしまいます。これはindex指定による要素追加と比較すると2倍のメモリを使用することになるため、大量データを扱う際は意識するべきことかなと思います。
StreamWriterの使用とmergeアルゴリズムの見直し
Sheet内のデータ管理のためのモデルは以下のようになっています。
// CellWrite represents a single cell write operation with row/column coordinates, value, and style. type CellWrite struct { Row int Col int Value interface{} Style int // Style ID for the cell } // CellWrites is a slice of CellWrite that can be sorted by row and column. type CellWrites []CellWrite // SheetWrites holds all cell writes for a specific sheet. type SheetWrites struct { Cells CellWrites Modified bool }
以下の流れでレポート作成が実施されています。
- 空のエクセルファイルの作成
- Excelテンプレートの内容をSheetWritesにまとめる。(SheetWritesForTemplateと以下で記載)
- チャート設定を実行。取得したデータをSheetWritesにそれぞれまとめる。(SheetWritesForChartと以下で記載)
- Sql設定を実行。取得したデータをSheetWritesにそれぞれまとめる。(SheetWritesForSqlと以下で記載)
- SheetWritesForTemplate、SheetWritesForChart、SheetWritesForSqlを優先順位に従って2pointersアルゴリズムを使用してマージ。2pointersアルゴリズムの計算量の観点からSheetWritesForChart、SheetWritesForSqlの優先度は出力データ量の少ない方を優先度高めとする。
- マージされたデータをExcelファイルに書き込み
- ファイルの保存
2pointersアルゴリズムは以下のように実装しています。
// mergeSortedCellWrites merges two sorted CellWrites arrays using two-pointer algorithm // returns a new SheetWrites with merged and sorted cells // sheet2 has higher priority and will override cells from sheet1 when positions overlap func mergeSortedCellWrites(sheet1, sheet2 *model.SheetWrites) model.SheetWrites { result := model.SheetWrites{ Cells: make(model.CellWrites, 0), Modified: false, } // Handle nil cases if sheet1 == nil && sheet2 == nil { return result } if sheet1 == nil { result.Cells = append(result.Cells, sheet2.Cells...) result.Modified = sheet2.Modified return result } if sheet2 == nil { result.Cells = append(result.Cells, sheet1.Cells...) result.Modified = sheet1.Modified return result } // Pre-allocate the result array with the maximum possible size // This is the sum of both arrays minus potential overlaps maxSize := len(sheet1.Cells) + len(sheet2.Cells) result.Cells = make(model.CellWrites, maxSize) // Initialize pointers for both arrays and result array i, j, k := 0, 0, 0 // Process both arrays using two-pointer technique for i < len(sheet1.Cells) && j < len(sheet2.Cells) { cell1 := sheet1.Cells[i] cell2 := sheet2.Cells[j] // Compare cells by row and column if cell1.Row < cell2.Row || (cell1.Row == cell2.Row && cell1.Col < cell2.Col) { // cell1 comes before cell2, add cell1 result.Cells[k] = cell1 i++ k++ } else if cell1.Row > cell2.Row || (cell1.Row == cell2.Row && cell1.Col > cell2.Col) { // cell2 comes before cell1, add cell2 result.Cells[k] = cell2 j++ k++ } else { // Same position, sheet2 (higher priority) overrides sheet1 result.Cells[k] = cell2 i++ j++ k++ } } // Process remaining cells from sheet1 for i < len(sheet1.Cells) { result.Cells[k] = sheet1.Cells[i] i++ k++ } // Process remaining cells from sheet2 for j < len(sheet2.Cells) { result.Cells[k] = sheet2.Cells[j] j++ k++ } // Trim the result array to the actual size used result.Cells = result.Cells[:k] result.Modified = true return result }
2pointersアルゴリズムとはsort済みの複数の配列を1つの配列にsortした状態でマージしたい場合に使用されるアルゴリズムです。以下のように実装することも可能ですが、この場合、sort処理のところでO((m+n)log(m+n))の平均時間計算量が発生します。(sort.Sortは内部でquick sortを使用しています。)2pointersアルゴリズムは最悪計算量がO(m+n)なので効率が良いです。
mergeSheetWrite := append(sheetWriteForChart, sheetWriteForSql...) // len= m + n sort.Slice(mergeSheetWrite.Cells, func(i, j int) bool { if mergeSheetWrite.Cells[i].Row != mergeSheetWrite.Cells[j].Row { return mergeSheetWrite.Cells[i].Row < mergeSheetWrite.Cells[j].Row } return mergeSheetWrite.Cells[i].Col < mergeSheetWrite.Cells[j].Col })
また、SheetWritesForChart、SheetWritesForSqlの優先度は出力データ量の少ない方を優先度高めとしているのは2pointersアルゴリズムの性質の都合です。例えば、SheetWritesForTemplateのCellsの要素数が10、SheetWritesForChartのCellsの要素数が20、SheetWritesForSqlのCellsの要素数が500万だとします。この時要素数の大きい方からmergeする場合の最悪時間計算量が(10+500万) + (500万10 + 20) = 1000万30となりますが、要素数の小さい方からmergeする場合の最悪時間計算量が(10+20) + (30 + 500万) =500万60となります。そのため、要素数の少ない方を優先度高めにしています。
今回の件で学んだこと
今回数千万件のデータ量を扱う上で学んだことは以下の2点です。
- sortアルゴリズムは大量データを扱う際はボトルネックになりやすいので最小限の回数で効率的に使用しなければいけない。
- appendは大量データを扱う際はボトルネックになりやすいので最終的に必要となる配列の要素数分のメモリを事前に用意して、indexによる要素追加にできる限りしなければいけない。
現状の課題
今回のレポート作成機能の開発によりインフラスペックを大きく上げてしまいました。インフラコストの大きな上昇を避けるためにはアプリケーション側での最適化だけでなく、インフラ側での最適化も必要になります。具体的には、AWSのECSのタスク定義でレポート作成用のタスク定義を用意し、以下の流れで処理を行う必要があると思っています。
- レポート作成のリクエストが発生したら、SQSにリクエストを保持しておく
- レポート作成用のタスク定義を実行して、コンテナを立ち上げる。
- コンテナが立ち上がり次第、SQSに溜めていたリクエストを実施する。
このようにすることで、レポート作成に耐えうるためのコンテナを常時運用する必要がなくなります。また、SQSの溜まっているリクエスト数に応じてオートスケーリングをするなど柔軟な負荷対策も可能となるため、今後は上記のような改修をしてインフラコストの削減をしていこうと思っています。
採用情報
弊社では、プロダクト開発チームのメンバーを積極採用中です!